태그 기반 파일 관리 시스템 개발기 - 1
Written in 2022/11/28 18:18:31 UTC, categoried as web
나는 예전에 자작 NAS를 잠깐 굴린 적이 있었다. 강력한 zfs를 활용한 truenas라는 NAS용 OS를 올려서 썼는데, 아무리 OS가 좋아도 막상 맘에 드는 파일 관리 시스템이 별로 없었다. 그나마 minio라는, AWS S3 API를 본따 만든 오픈소스 오브젝트 스토리지 서비스가 괜찮았지만 상당한 버그와 아쉬운 사용성 때문에 얼마 가지 않아 포기했다. 그러던 요즘 문뜩 NAS가 있으면 좋겠다는 생각이 들었고, 이번에는 내가 직접 파일 관리 시스템을 만들어보기로 했다.
요구사항
내가 설정한 요구사항은 아래와 같다.
- 여러 사용자가 손쉽게 파일을 올리고 내릴 수 있어야 한다. 사용자간 파일 소유권은 구분하지 않는다.
- 수많은 파일이 저장될 것이다. 이들의 효율적인 관리를 위해, 전통적인 디렉터리 구조를 벗어나 태그 기반으로 파일을 구분해야 한다.
- 파일을 그룹지어 컬렉션을 만들 수 있어야 한다.
- 파일 및 태그, 컬렉션들을 빠르게 색인할 수 있어야 한다.
NAS위에서 장시간 동작해야 하므로, 시스템 리소스를 최대한 덜 차지하면서도 안정적이야 한다.
여기서 특이한 점은 태그 기반이라는 점이다.
태그 기반 파일 시스템
전통적인 모든 파일 시스템들은 디렉터리 기반이다. 하지만 이 디렉터리 기반 파일 시스템의 최대 문제는, 파일이 여러 그룹에 동시에 속하는 상황을 표현하기 어렵다는 것이다. 파일 A가 1 그룹과 2 그룹에 동시에 속한다면, 전통적인 시스템에서는 /1/2/A 및 /2/1/A 모두로 표현할 수 있다. 이는 그룹간에 순서가 존재한다는 말이고, 그룹이 아주 많아질 경우 혼란을 야기한다. NAS같은 파일 공유 서비스에서는 그룹이 많은 경우가 다반사다. 좋지 않다.
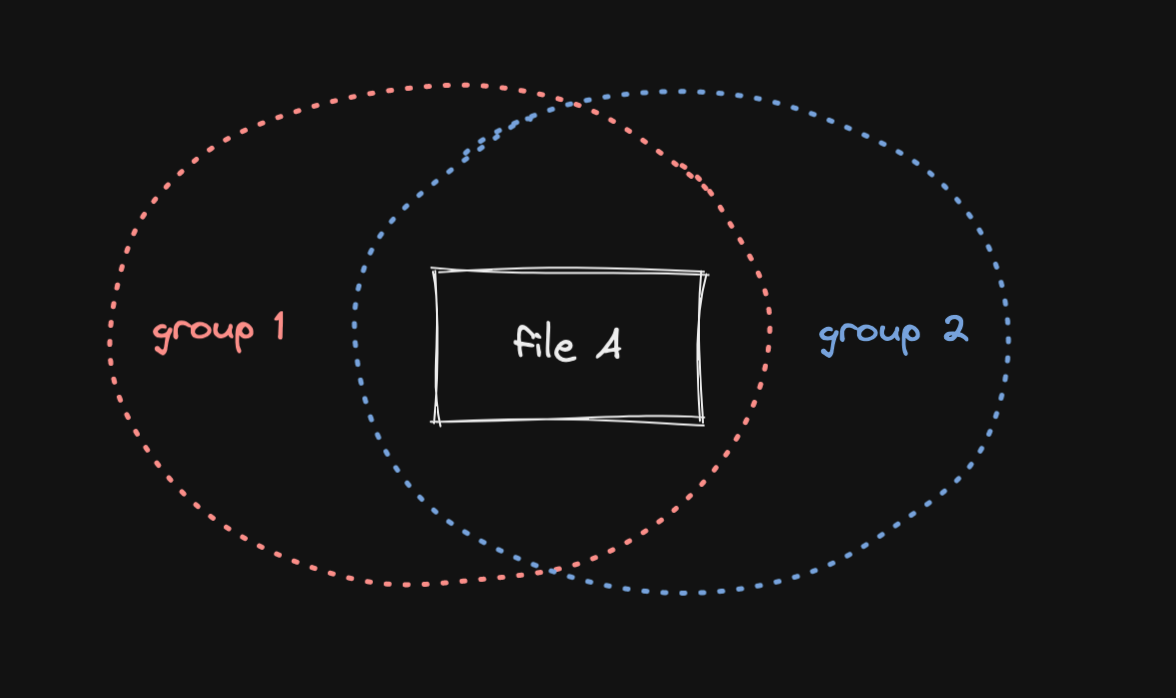
반면, 태그 기반 파일 시스템에서는 디렉터리라는 개념이 존재하지 않는다. 대신 태그를 사용한다. 태그를 파일에 붙여두기만 하면, 언제든지 특정 태그를 가진 모든 파일을 한눈에 볼 수 있다. 이제는 파일이 어디있는지 기억해낼 필요가 없는 것이다.
태그 값
파일에 태그를 붙여 관리하는 것만으로도 훌륭하지만, 나는 태그에 값을 도입해보기로 했다. 태그 값이란, 말 그대로 태그가 값을 가질 수 있는 것이다.
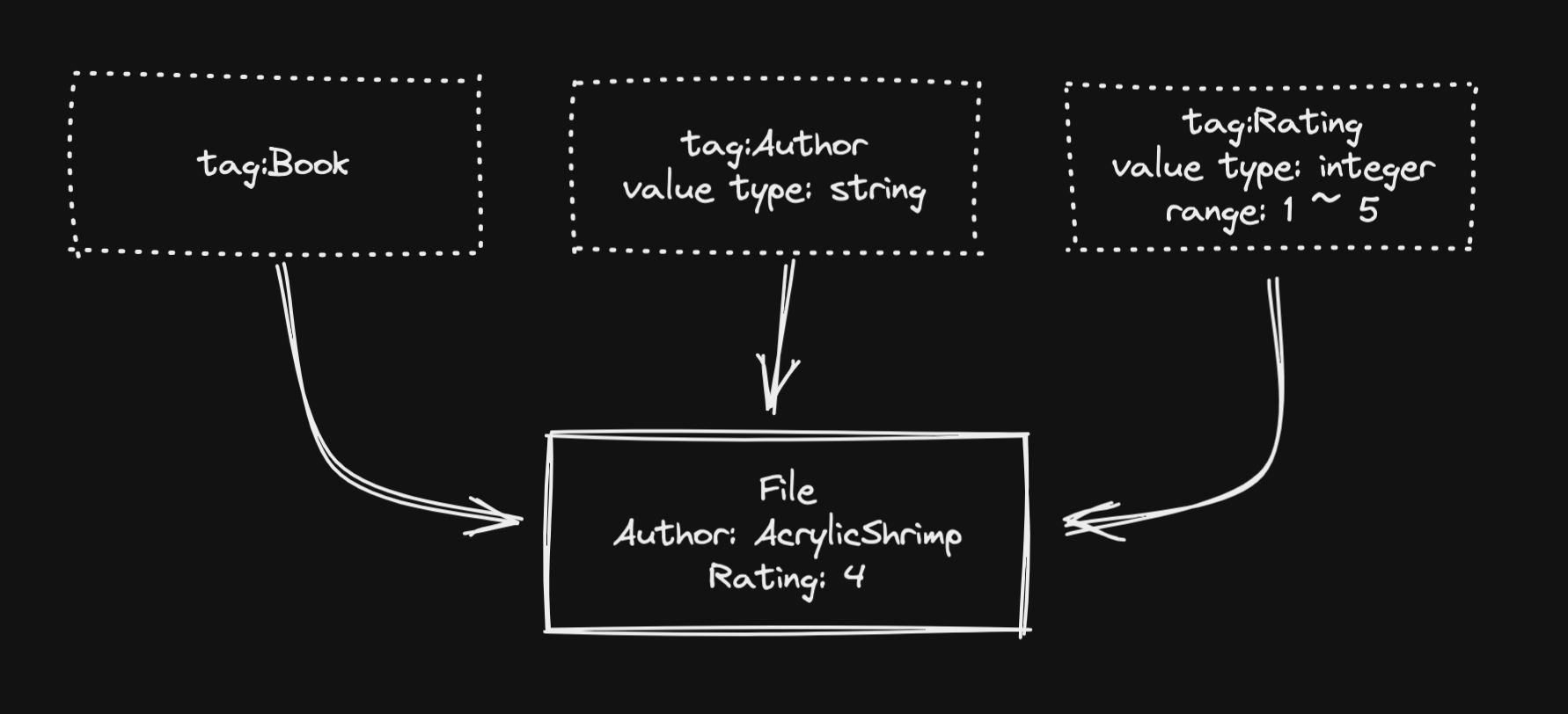
파일에 태그를 붙이면, 태그에 지정된 값을 파일이 가진다. 이는 원하는 파일을 필터링할 때 유용하게 사용할 수 있다. 여기서 한가지 중요한 컨셉은 validation이다. 태그에 원하는 값 타입을 부여하고 나서, 파일이 가진 값이 특정한 조건을 통과하는지 검사할 수 있다. 이는 시스템에서 자동으로 처리하며, 잘못된 값을 가질 경우 거부함으로써 정합성을 보장할 수 있다. 예를 들면, Rating 태그는 값 타입이 integer이고 범위는 [1, 5]이다. 이 조건을 만족하지 못하면 시스템이 거부할 것이다.
컬렉션
컬렉션은 태그의 모음이다. 어떠한 파일을 주어진 컬렉션에 포함하려면, 해당 컬렉션이 가진 모든 태그와 값을 파일 또한 가지고 있어야 한다. 파일에 일일히 적절한 태그를 붙이는 것은 상당히 귀찮고 실수할 여지가 큰 작업이다. 컬렉션을 도입하면 이러한 작업을 일부 자동화할 수 있을 것이다.
PoC
원하는 요구사항과 구현할 컨셉을 모두 정리했으므로, 실제 동작하는 프로토타입을 만들어야 한다. 먼저 핵심이 되는 데이터베이스를 간단하게 설계해 봤다.
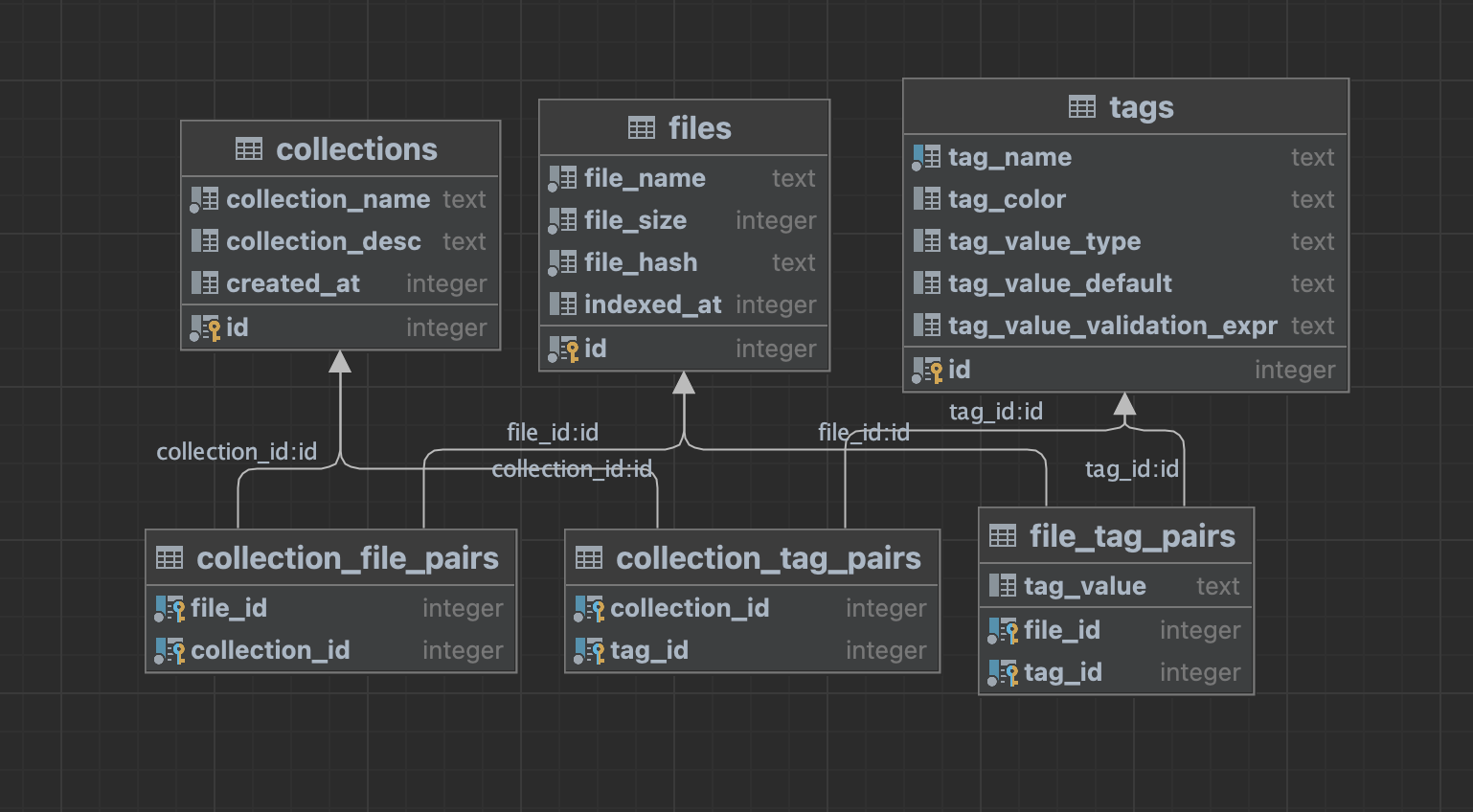
...뭔가 특이한 구조가 된 것 같지만, 괜찮다. 동작만 잘 하면 되지! 내 생각에는 문제 없이 돌아갈 것 같다. 연관 관계가 좀 복잡하지만, 이보다 더 나은 설계는 내 수준에선 아직 어렵다. 흑흑.
기술 스택
이제 기술 스택을 정해보자. 사용할 기술 스택은 NAS에서 장시간 실행될 것을 전제로 해야한다. 먼저 성능을 위해 Rust를 선택했다. 익숙하기도 하고. 데이터베이스로는 최대한 외부 서비스에 의존하지 않도록 SQLite를 골랐다. 남은건 full-text search를 위한 검색 엔진과 웹용 프레임워크 정도인 것 같다. 프레임워크로는 actix를 써보려고 한다. 다만 이 녀석은 너무 로우레벨이라 multipart 처리가 까다로운 것으로 기억하는데, 그래도 불가능하지는 않을 테니 일단 선택. 검색 엔진은 이전에 써보고 좋다고 느낀 meilisearch를 쓸 생각이다. 하지만 meilisearch는 임베드를 지원하지 않는다. 이러면 외부 종속성으로 같이 띄워줄 필요가 있다. 다행히 truenas는 Docker 기반으로 컨테이너 실행을 지원하는데, 이렇게 구성하면 괜찮을 것 같다. 정리하면 아래와 같다.
뭘까, 기술 스택만 골랐는데도 벌써 속이 든든하고, 개발이 잘될 것만 같고... 아무튼, 요구사항과 기술 스택 모두 정했으니 이제 빡센 프로그래밍만이 남았다. 음, 귀찮으니까 이건 나중에 해야지.