ex-lang 개발기 1
Written in 2023/04/03 21:09:17 UTC, categoried as compiler
새로운 언어를 개발해보고 있다. 이름은 ex라 지었는데, 별다른 의미는 없다. 지금까지의 컴파일러 개발 경험을 살려 실제로 활용할 수 있는 언어를 디자인하는 것과, 컴파일러를 부트스트랩하는 것이 최종 목표다.
https://github.com/AcrylicShrimp/ex
현재 기본적인 컴파일러 동작까지 구현했으며, 컴파일러 프론트엔드의 최종 생산물인 IR을 간단히 실행해볼 수 있는 작은 VM이 들어있어 테스트 코드를 실행해볼 수 있다. 컴파일러를 본격적으로 구현하면서 많은 문제를 경험하고 해결했는데, 이 개발기에 내가 겪은 모든 것을 정리해 적어본다. 이번 한번에 끝낼 건 아니고, 개발을 진행하면서 계속 적을 생각이다.
Node Id
AST(Abstract Syntax Tree)는 컴파일러가 생성하고 사용하는 데이터 구조의 일종으로, 소스코드 그 자체를 표현한다. 컴파일러란 기본적으로 소스코드를 읽고 이것을 다른 형태로 변환하는 소프트웨어이므로, 이 AST는 여러 패스에 걸쳐 폭넓게 사용되는 매우 중요한 요소다. 컴파일러의 각 패스는 AST 또는 그에 준하는 입력을 받아 각종 처리를 수행하고, 분석한 정보를 제공하거나 AST를 수정한다.
어떠한 패스가 AST를 분석해 정보를 제공하려는 경우, 일반적으로 해당 정보는 AST에 의존적이다. 예를 들어 각 함수에 대한 심볼 테이블을 분석해 제공하는 패스가 있다면, 이 패스가 생성하는 심볼 테이블 내에는 각 심볼의 종류와 위치 같은 정보가 포함될 것이다. 이 때, 심볼 테이블의 아이템 하나는 AST 노드 하나에 대응한다. 이처럼 메타데이터가 특정 AST 노드에 의존하거나 노드를 가리켜야 하는 일은 매우 잦다.
또한, 실제로 어떤 패스가 있는지는 컴파일러 구현마다 다르며, 이는 컴파일러 개발을 진행하며 점차 달라지기도 한다. 따라서 각 메타데이터는 AST 노드와 분리해 운용하는 것이 좋다. AST는 고유 문법에 따른 형태를 가지며, 메타데이터는 컴파일러 구조와 언어가 제공하는 기능에 영향을 받는다. 두 요소의 수명 주기가 다르다는 말이다. 따라서 각 AST 노드가 모든 메타데이터를 직접적으로 소유하고 있는 것은 효율적이지 않다(때론 불가능하다). 이를 해결하는 가장 쉬운 방법이 개별 노드에 고유한 ID를 부여하는 것이다. 노드 ID가 AST와 메타데이터 사이의 직접적인 의존 관계를 없앰으로써 두 요소를 효과적으로 분리한다. 뿐 만 아니라, 임의의 노드가 주어졌을 때 해당 노드와 관련된 메타데이터에 빠르게 접근할 수 있다.
컴파일 도중 생성하는 메타데이터는 생각 이상으로 다양하다. 표현식 노드의 타입일 수도 있으며, 변수 선언 노드의 집합일 수도 있다. 어떤 메타데이터는 다른 메타데이터의 조합으로 생기는 경우도 많다. 이런 무수한 메타데이터를 노드 ID 없이 관리하는 것은 매우 어렵다.
Desugaring and HIR
디슈거링(Desugaring)이 무엇인지 이해하기 위해서는 먼저 문법 설탕이라 부르는 Syntactic Sugar에 대해 짚고 넘어가야 한다. 어렵지 않다! 알게모르게 자주 접했을 것이다. 먼저 아래 코드를 보자.
typedef struct Foo {
int member;
} Foo;
int main()
{
Foo foo;
Foo *bar = &foo;
bar->member = 10;
}
위 코드에서는 -> 연산자를 활용해, 포인터를 통해 간접적으로 member에 접근하고 있다. 여기서 -> 연산자를 사용하지 않고도 같은 동작을 수행할 수 있을까?
typedef struct Foo {
int member;
} Foo;
int main()
{
Foo foo;
Foo *bar = &foo;
(*bar).member = 10;
}
그렇다. (*bar).member 형태로 바꿔 쓰면 -> 연산자를 사용하지 않고도 같은 동작을 수행할 수 있다. 이것이 바로 문법 설탕, Syntactic Sugar의 대표적인 예시다. 즉 문법 설탕이란, 기존에 있는 문법으로도 같은 동작을 달성할 수 있지만, 더 읽기 쉽거나 작성하기 쉬운 대체 문법을 말한다.
그렇다면 문법 설탕은 어떤식으로 구현할 수 있을까? 문법 설탕을 새로운 문법으로 간주하고 이들에 대한 처리를 직접 수행해도 되지만, 이렇게 하면 컴파일러는 같은 동작을 하는 여러가지 바리에이션을 모두 처리해야 한다. 이는 컴파일러의 복잡성을 높이고 관리를 어렵게 한다. 그 대신, 일반적으로 컴파일러는 문법 설탕을 만나면 이것을 원래 코드로 바꿔서 컴파일한다. 이후 단계에서는 문법 설탕에 대해 알 필요가 없으므로, 구현이 단순해진다. 이 과정을 디슈거링, Desugaring이라고 한다. 결론적으로, 디슈거링은 문법 설탕을 구현하는 여러 방법중 하나인 것이다. 이 디슈거링은 AST를 직접 조작하여 처리하는 방법이 있고, 그 이후 단계에서 처리하는 경우도 있다. 이 프로젝트에서는 AST를 조작하는 방법은 선택하지 않았는데, 그러한 선택에는 나름의 이유가 있다.
AST
렉서와 파서를 구현하면 AST를 얻을 수 있다. 이 AST의 목적은 구문 분석을 완료한 소스코드를 온전히 표현하는 것으로, 원래 소스코드의 정보를 손상 없이 담고 있는 것이 유리하다. 이 정보는 이후 컴파일 단계 뿐만 아니라 LSP(Language Server Protocol)나 포매터를 구현하는 등 여러 관련 도구를 개발하는데도 매우 유용하게 활용할 수 있다. 그런데 디슈거링을 AST 위에 직접 수행하면 크게 두 가지 문제가 생긴다.
AST가 실제 소스코드와는 다른 형태로 변할 가능성이 있다.AST에 의존하는 컨텍스트가 여전히 문법 설탕에 대해 알고 있어야 한다.
첫 번째 문제는, 필요한 경우에 디슈거링을 수행하지 않음으로써 회피할 수 있다. 하지만 두 번째 문제는 그렇지 않다. 문법 설탕은 그 자체로 곧 문법이고, 이는 AST에서 정의하고 있기 때문이다. 이러한 문제를 해결하기 위해, 이 프로젝트에서는 HIR을 도입하기로 결정했다.
HIR and Lowering
HIR(High-level Intermediate Representation)은 IR(Intermediate Representation)의 일종이다. 이 프로젝트에서 HIR은 AST 이후에 생성한다. HIR은 AST와 거의 유사하지만 몇 가지 차이점을 가지고 있다.
HIR에서 등장하는 모든Symbol은 분석이 완료된 상태이다. 다시 말해, 각Symbol은 이것이 어떤 변수나 함수를 가리키는지 알고 있다.HIR은 디슈거링이 완료된 상태이다.
즉, HIR은 AST의 저수준(기계가 사용하기 쉬운) 표현이다. 컴파일러는 AST를 생성한 뒤 몇 가지 처리를 거쳐 필요한 정보를 얻어내고, 최종적으로 디슈거링을 수행해 HIR로 바꾼다. 이렇게 고수준 표현을 저수준 표현으로 변환하는 작업을 Lowering이라고 한다. 따라서 디슈거링은 AST를 HIR로 Lowering하는 과정에서 일어난다고 할 수 있다.
HIR은 AST보다 실질적으로 표현할 수 있는 구문의 개수가 적다. 원래 소스코드의 문법, AST가 표현할 수 있는 문법의 일부는 HIR에서는 지원하지 않는다는 이야기가 된다. 이러한 것들이 디슈거링의 대상이다. 컴파일러는 AST의 모든 노드를 방문하며, 만나는 모든 문법을 HIR로 표현하려 시도한다. 그러나 일부 문법은 HIR로 바로 바꿀 수 없다. 대응하는 문법이 HIR에 없을 수도 있기 때문이다. 이 경우 HIR에서 지원되는 다른 대체 표현으로 바꾼다. 예를 들어, 아래와 같은 코드를 HIR로 변환한다고 가정해보자.
fn main() {
let i = 0;
while i < 10 {
println(i);
i += 1;
}
}
컴파일러가 while 문을 만나면 디슈거링이 일어난다. 그도 그럴 것이, HIR에는 while이 존재하지 않는다! 놀랐을지도 모르겠다. 사실 while은 필요하지 않은데, loop와 if, 그리고 break의 조합으로 바꿔서 표현할 수 있다. 다시 말해, 위 코드는 아래와 같이 바뀐다.
fn main() {
let i = 0;
loop {
// condition part from while
if ! (i < 10) {
break;
}
// body part from while
{
println(i);
i += 1;
}
}
}
위의 두 코드는 정확히 같은 동작을 한다. 이러한 변환은 AST 이후 단계에서 while에 대해 알 필요를 없애줌으로써, 컴파일러 개발을 더 쉽게 해준다. 다르게 표현하면, "단순"해졌다. 그러나 너무 과도한 단순화는 타겟 머신의 native 수준에서 지원되는 기능을 활용하기 어렵게 만드는 등, 성능 면에서 손해를 볼 수도 있다. 항상 적절한 균형이 필요한 것이다.
이렇게 모든 AST의 노드가 HIR로 변환되면 Lowering이 끝난다. 이후에는 HIR을 이용한 각종 분석과, 타입 추론 및 타입 확인 과정 등을 수행하며 컴파일이 계속된다.
Type Inference
올바른 컴파일을 위해서 타입은 빠질 수 없는 중요한 것이다. 그러나 때로는 타입을 적는 일을 귀찮고, 반복적이고, 기계적이라 느끼는 것은 사실이다. 타입을 명시적으로 알 수 있는 상황에 한해서, 타입을 명시하지 않아도 괜찮도록 해주는 타입 추론(Type Inference)은 사실상 거의 대부분의 정적 타입(Statically Typed) 언어에서 제공하는 기능으로, 프로그래머의 수고를 크게 줄인다. 이는 컴파일러가 의미를 분석하는 단계(Semantic Checking)에서 타입을 추론해주기 때문에 가능한 일이다. 프로그래머가 작성한 코드 일부에 타입이 빠져있더라도, 문맥을 파악해 빠진 타입을 추론하고 채워준다.
Type System
타입 시스템은 규칙의 집합으로써, 타입이 언제 어떻게 결정되는지 정의한다. 타입 추론은 주어진 타입 시스템 아래에서 최대한 많은 규칙을 적용해 올바른 타입을 찾아내는 것으로, 타입 시스템이 달라지면 타입 추론의 기능과 동작도 크게 달라진다. 프로그래밍 언어마다, 또는 컴파일러 구현마다 실제로 제공하는 타입 추론의 기능에는 많은 차이가 있다. 프로그래밍 언어마다 타입 시스템이 다르기 때문이다. 또한 프로그래밍 언어의 설계 사상이나 문법적인 특성에서 기인한 요소도 존재한다.
이 프로젝트의 경우 Rust의 영향을 크게 받았는데, Rust에서는 HM Type System을 사용해 타입 추론을 진행한다. 이 프로젝트 또한 같은 타입 시스템을 사용하고 있다. 여기서 HM Type System의 이론적 배경을 자세히 설명하지는 않겠다. 사실 별 거 없기도 하다. 프로그래머라면 많이 접했을 타입 시스템이고, 그것을 좀 더 수학적으로 표현했을 뿐이다.
Constraint and Solving
타입 추론은 타입 시스템의 규칙을 적용하는 방식으로 동작한다고 했다. 이 프로젝트에서는 방향성을 가지는 제약 조건(Constraint)을 설정하고 그 해를 찾아가도록 구현했다. 제약 조건을 변(Edge)으로 삼는 일종의 그래프(Graph)인 것이다. 그렇다면 꼭짓점(Vertex)는 무엇인가? 바로 타입 변수이다. 꼭짓점을 타입 변수, 변을 제약 조건으로 하는 그래프를 풀어 모든 꼭짓점의 타입을 확정하기만 할 수 있다면, 타입 추론이 완료된다.
타입 변수(Type Variable)란, 타입이 필요한 모든 항목에 대해 실제 타입 대신 부여한 간접 타입이다. 타입 추론 이전에는 실제 타입이 뭔지 알 수 없으므로, 타입 추론을 진행하기 전에 먼저 임시로 타입을 부여하는 것이다. 이후 추론이 완료되면 일괄적으로 타입이 확정되며, 이 때 타입 변수가 실제 타입과 연결된다. 이렇게 함으로써 타입 확정을 미룰 수 있고, 실제 타입을 알지 못하더라도 타입간 관계를 설정할 수 있다.
그래프를 구성하기 위해서는 HIR이 필요하다. HIR의 모든 노드를 방문하며 각 표현식(Expression) 노드에 타입 변수를 부여하고, 주어진 맥락에 따라 타입 변수 사이의 제약 조건을 설정한다. 제약 조건에는 두 가지가 있다. 하나는 A is equal to B 관계이며, 다른 하나는 A is subtype of B 관계이다.
Equal-to Relationship
A is equal to B 관계는 가장 직관적인 것으로, B의 타입이 결정되면 A의 타입도 같은 것으로 결정되는 관계를 나타낸다. 이 관계는 역도 성립한다. A의 타입이 먼저 결정되면 B의 타입도 결정되는 것이다. 제약 조건이 방향성을 가지는 점을 생각하면, 이는 보기보다 복잡한 풀이법을 요구한다. 이를 해결하는 자세한 내용은 후술한다.
Subtype-of Relationship
A is subtype of B 관계는 쉽게 말해서, A을 B에 대입할 수 있는 관계라고 할 수 있다. A가 B의 파생 타입인 것이다. 이 때, A와 B의 타입이 항상 일치할 필요는 없다. B가 A와는 다른, 더 일반적인(General) 타입인 경우 A와 B의 실제 타입이 다르다고 하더라도 대입이 가능하다. OOP(Object-Oriented Programming)에서 자주 볼 수 있는 Polymorphism을 떠올리면 된다. 어떠한 클래스 A가 인터페이스 B를 구현하는 경우, A 타입의 인스턴스는 B 타입 객체에 대입할 수 있다. A is subtype of B 관계는 바로 이것을 나타내는 것이다. 당연하지만 역은 성립하지 않는다.
Graph Construction
이제 그래프를 구성하는 방법을 자세히 알아보자. 아래에 예시 코드를 준비했다.
fn main() {
let foo; // type_var(1)
let bar; // type_var(2)
if foo { // type_var(3)
bar // type_var(4)
= baz(); // type_var(5)
}
let bazz = // type_var(6)
foo as u32 // type_var(7)
+ // type_var(9)
bar; // type_var(8)
}
fn baz() -> u32 {
0xDEADC0DE
}
위 코드는 변수 foo를 할당되기 이전에 사용하므로 문맥적으로 올바른 코드는 아니지만, 타입 추론 단계까지는 컴파일이 가능한 코드다. 이 코드에 대해 그래프를 그리기 위해서는 아래와 같은 절차를 거치게 된다.
foo는let statement이므로 타입을 가진다.foo에type_var(1)를 할당한다.- 마찬가지로
bar에type_var(2)를 할당한다. if의condition에서,foo변수를 참조하고 있다. 이것도 하나의 표현식이므로,type_var(1)과는 별개로type_var(3)를 할당한다. 또한type_var(1)과type_var(3)는 본질적으로 동일한 것이므로, 이에 해당하는 제약 조건을 설정한다:type_var(3) is equal to type_var(1)if의condition에는bool타입에 대입 가능한 타입이 와야 함을 컴파일러는 알고 있다. 따라서type_var(3)에 다음과 같은 제약 조건을 설정한다:type_var(3) is subtype of concrete type(bool)if의 본문에서,baz의 반환값을bar에 대입하고 있다.bar는 변수 참조식이므로 제약 조건을 설정할 수 있다:type_var(4) is equal to type_var(2)baz는 함수이므로,baz의 반환형이u32임을 타입 추론 이전에 알 수 있다. 따라서baz()표현식에 제약 조건을 설정할 수 있다:type_var(5) is equal to concrete type(u32)bar에baz()를 대입하고 있다. 역시 제약 조건을 설정할 수 있다:type_var(5) is subtype of type_var(4)bazz에type_var(6)을 할당한다.bazz대입문의 오른쪽 표현식에서,foo변수 참조식에type_var(7)을 할당한다.as표현식으로 변환을 수행했으므로 타입을 확정할 수 있다. 제약 조건을 설정한다:type_var(7) is equal to concrete type(u32)bazz대입문의 오른쪽 표현식에서,bar변수 참조식에type_var(8)을 할당하고 제약 조건을 설정한다:type_var(8) is equal to type_var(2)bazz대입문의 오른쪽 표현식은 최종적으로+이항 연산이다. 이 표현식에type_var(9)를 할당하고 제약 조건을 설정한다:type_var(9) is equal to binary_op(+, type_var(7), type_var(8))- 마지막 제약 조건을 설정한다:
type_var(9) is subtype of type_var(6)
이를 정리하면 아래와 같은 제약 조건들을 얻을 수 있다.
type_var(3) is equal to type_var(1)type_var(3) is subtype of concrete type(bool)type_var(4) is equal to type_var(2)type_var(5) is equal to concrete type(u32)type_var(5) is subtype of type_var(4)type_var(7) is equal to concrete type(u32)type_var(8) is equal to type_var(2)type_var(9) is equal to binary_op(+, type_var(7), type_var(8))type_var(9) is subtype of type_var(6)
Graph Solving
이로써 타입 변수 할당과 제약조건 설정이 모두 끝났다. 이렇게 만들어진 그래프에서 해를 찾아내면 타입 추론이 완료된다. 해를 찾는 방법은 기본적으로 Graph Unification이라고 하는 방법을 사용한다. 주어진 제약 조건을 만족하는 가장 일반적인 해를 찾아내는 것이다. 이 프로젝트에서 구현한 알고리즘으로 이 그래프를 풀어보자.
그래프를 푸는 첫 단계는 모든 A is equal to B 관계의 제약 조건을 전파하는 것이다. A가 참여하는 모든 A is subtype of B 관계를 B의 새로운 제약 조건으로 추가한다. 참여한다는 것은 제약 조건의 방향과 관련 없이 A 자리와 B 자리 중 어디에서든지 등장하는 것을 말한다. B가 참여하는 관계 또한 A에 새로운 제약 조건으로 추가한다. 이렇게 A와 B 모두 동일한 조건을 가지게 하는 것이다. 이 과정을 거친 뒤에 새롭게 추가한 제약 조건은 아래와 같다.
type_var(1) is subtype of concrete type(bool)type_var(5) is subtype of type_var(2)type_var(5) is subtype of type_var(8)
두번째 단계는 가능한 모든 A is equal to B 관계를 풀어 타입을 확정한다. 우리가 가진 제약 조건중 풀 수 있는 관계는 아래와 같다. 두 타입 변수의 타입을 확정하고 제약 조건에서 제거한다. A 및 B 모두 타입을 확정했으므로, 이러한 제약 조건은 제거해도 안전하다.
type_var(5) is equal to concrete type(u32)type_var(7) is equal to concrete type(u32)
세번째 단계다. 모든 A is subtype of B 관계에 대해, B 자리에 타입 변수가 있고 A와 B 모두의 타입을 확정했다면 제거한다. 이 조건을 만족하지 않는 관계에 대해, A 자리의 타입 변수의 타입을 확정했다면 제거한다. 이 예시에서 아직은 제거할 수 있는 제약 조건은 없다. 이 제거 연산 역시 안전하다.
네번째 단계는 모든 타입 변수에 대해, 모든 A is equal to B 관계중 해당 변수가 A 자리에 있는 경우의 수를 센다. 한 개도 없다면 이 타입 변수는 외부로부터 타입을 확정받을 수 있는 기회가 없다는 뜻이 되므로, 스스로 타입을 확정해야 한다. 그러한 타입 변수에 대해, 가장 일반적인 타입을 찾아 확정한다. 이 경우 타입은 해당 타입 변수가 참여하는 모든 A is subtype of B 관계를 모으면 알 수 있다. 제시한 상황에서 확정할 수 있는 타입 변수는 아래와 같다. 이전 두 단계와 다르게 타입을 확정한 제약 조건을 제거하지 않음에 주목하자.
type_var(1) is booltype_var(2) is u32
위 단계를 모두 마치면 다시 두번째 단계로 돌아가 작업을 수행한다. 이 반복은 그래프에 변화가 없어지면 종료한다. 종료한 이후, 타입을 확정하지 못한 타입 변수가 하나 이상 존재하면 타입 추론은 실패하며, 프로그래머에게 하여금 더 많은 타입을 명시하도록 유도한다. 최종적으로 위 예제에서 만든 그래프를 풀면 아래와 같은 결론을 얻는다.
type_var(1) is booltype_var(2) is u32type_var(3) is booltype_var(4) is u32type_var(5) is u32type_var(6) is u32type_var(7) is u32type_var(8) is u32type_var(9) is u32
이상 타입 추론의 자세한 과정을 알아보았다. 다만 위에서 소개한 방법은 이 프로젝트에 국한된 것이며, 프로그래밍 언어의 스펙이나 타입 시스템이 달라지는 경우에는 적절한 수정을 가해야 한다. 또한 위 방법은 이 프로젝트에 구현한 방법과 정확히 일치하는 것은 아니다. 설명을 위해 일부 내용을 생략하거나 단순화한 부분이 존재한다.
CFG
CFG란 Control Flow Graph의 약자로써, 쉽게 말해 프로그램의 흐름을 그래프로 나타낸 것이다. 여기서 흐름이란 Control Flow, 즉 실행 순서를 말한다. CFG는 주로 Basic Block을 정점으로 하고 Branch(흐름 제어 명령)을 간선으로 하는 방향성 그래프로 표현한다. LLVM을 사용해 봤다면 익숙할 것이다. 이렇게 그린 CFG에는 몇가지 제약 조건이 있다.
CFG는 함수 하나에 대한 흐름을 표현한다. 함수간 호출 그래프는Call Graph라 부른다.Basic Block내에는 어떠한 흐름 제어 명령도 없다. 다시 말해, 모든Basic Block은 흐름을 넘겨받는다면 반드시 모두 실행된다.Basic Block끝에는 반드시 흐름 제어 명령이 하나 와야 한다. 이것이 위에서 말한 간선이다.
CFG Construction
대부분의 실행 흐름은 꽤 직관적이므로 쉽게 그려낼 수 있다. 그러나 일부 문법은 조금 까다롭다. 이 프로젝트에서는 특히 if, break 및 continue 구현에 시간을 많이 사용했다. 아래에서 각 경우에 대해 조금 더 깊게 서술한다.
CFG Construction - If
if는 얼핏 생각하면 어렵지 않을 것 같다. 조건에 따라 실행 흐름이 변경되는 단순한 구조를 가지고 있기 때문이다. 그러나 if에는 else if 및 else가 뒤이어 나타날 수 있다. 따라서 그냥 그리려고 하면 상당히 복잡해진다. 이 프로젝트에서는 이 문제를 스택을 활용해 해결한다. 이 과정을 유도해내기 위해 제일 간단한 if부터 생각해보자. 아마도 아래와 같이 그려볼 수 있을 것이다.
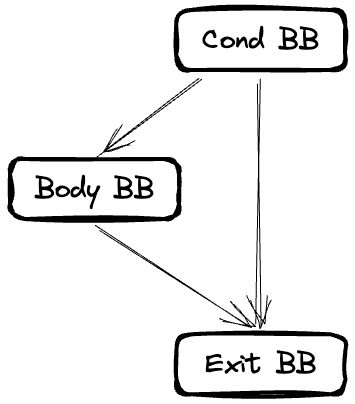
아직까지는 어렵지 않다. 이제 else if를 추가해보자.
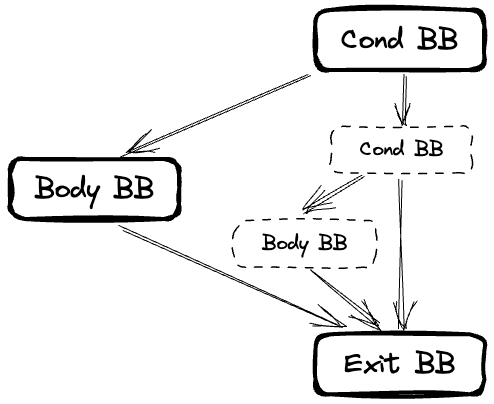
else 간선에 새로운 if가 추가된 형태가 된다. 여기서 마지막으로 else를 추가해보자.
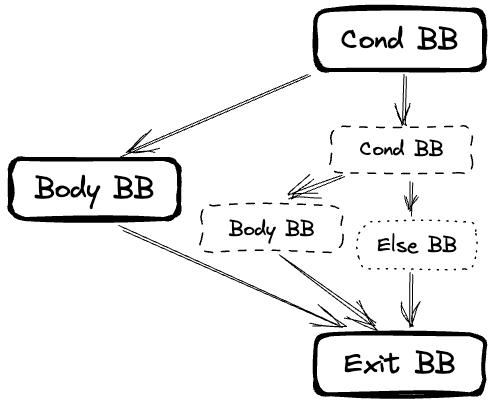
이렇게 완전한 형태의 if에 대해 CFG를 그렸다. 패턴이 보이는가? else if 및 else를 처리할 때, 항상 부모의 else 간선을 수정하게 된다. 이를 정리해보면 아래와 같다.
if를 처리해CFG를 구성하고Condition BB와Exit BB를 스택에 넣는다.- 모든
else if및else에 대해, 순서대로 처리해CFG를 구성하고Condition BB와Exit BB를 스택에 넣는다. - 스택에 있던 모든 아이템을 빼내면서 부모의
Exit BB에 간선을 연결한다.
이렇게 함으로써 if의 형태에 상관 없이 올바르게 CFG를 구성할 수 있다. 부모의 Exit BB가 수정되지 않는 경우 스택에 있던 아이템을 꺼내지 않고도 올바른 CFG를 구성할 수 있다. 이 때는 else if 및 else의 CFG를 구성할 때 부모(스택의 최상단 아이템)의 Exit BB에 간선을 연결하면 된다.
CFG Construction - Break and Continue
break 및 continue가 등장하는 경우, 컴파일러는 처리중인 Basic Block을 끊고 가장 가까운 루프의 시작점 또는 탈출점에 간선을 연결해야 한다. 이는 가장 가까운 루프의 시작점과 탈출점을 알아야 한다는 말이 된다. CFG를 구성하는 함수에 루프 컨텍스트를 파라미터로 받게 하면 구현할 수 있다. 끊어진 블럭은 더 이상 사용할 수 없으므로, 새로운 Basic Block을 추가하고 이후에 등장하는 코드를 새 Basic Block에 계속 처리하면 된다. 해당 Basic Block은 자연스럽게 사용하지 않는 Basic Block이 되며, 컴파일 도중 제거할 수 있다. return 또한 거의 비슷하게 처리하면 된다.
CFG Analysis
컴파일러는 구문 해석이 끝나면 CFG를 그려 각 함수의 제어 흐름을 분석한다. 이렇게 하면 몇가지 검사를 쉽게 수행할 수 있다. 이 프로젝트의 경우 아래 항목에 대한 검사를 위해 CFG 분석을 실시한다.
- 사용하지 않는 코드가 있는지 확인한다.
- 값을 반환하는 함수라면, 함수의 모든 부분에서 올바르게 값을 리턴하는지 확인한다.
첫 번째의 경우, 사용하지 않는 코드를 찾는 것은 CFG를 그려보면 아주 쉽게 찾을 수 있다. 임의의 Basic Block이 함수의 시작점으로부터 접근이 불가능하다면, 그 Basic Block은 어떠한 경우에도 실행할 수 없으므로 제거해도 안전하다. 이 프로젝트에서는 해당 코드에 대해 경고를 발생시키고 제거한다.
두 번째의 경우, 값을 반환하는 함수는 모든 실행 경로에서 반드시 올바른 값을 반환해야 한다. 값을 반환하지 않는 패스를 발견하면, 이는 해당 함수가 잘못 작성된 것이므로 컴파일을 거부한다. 이러한 실수는 발생하기 쉬우므로 반드시 검사해야 한다. 아래 예제 코드를 고려해 보자.
int foo(int a) {
if (a != 0) return 0;
}
모든 함수는 맨 마지막 문장을 실행하고 나면 자동으로 리턴한다. 따라서 위 함수는 사실 아래와 같은 함수다.
int foo(int a) {
if (a != 0) return 0;
return; // 함수 최하단에 return이 암시적으로 추가되었다.
}
이렇게 하면 실수가 좀 더 명백해진다. 함수 foo는 값을 반환하는 함수임에도 값을 반환하지 않는 실행 경로가 존재한다. 그렇다면 마지막에 return이 없는 함수는 전부 오류로 취급하면 해결할 수 있을까? 아래 코드도 생각해 보자.
int foo(int a) {
if (a == 0) return 0;
else return 1;
}
int bar() {
for (;;) if (rand() % 2 == 0) return 0;
}
위 두 함수는 마지막에 return이 없는 함수인데도 문제가 전혀 없는 코드다. 즉, 핵심은 값을 반환하지 않는 실행 경로의 존재 여부이다. 이는 CFG를 그린 뒤에, 함수의 탈출점이 시작점에서 접근 가능한지 확인하면 알 수 있다. 접근이 가능하다면, 해당 함수는 값을 반환하지 않는 실행 경로가 존재한다. 접근이 불가능하다면, 해당 함수는 어떻게든 값을 반환하거나 영원히 실행되는 함수다. 이 프로젝트에서는 해당 오류 검출을 위해 아래와 같은 방법을 사용했다.
- 주어진 함수에 대해,
CFG를 구성한다. - 함수의 탈출점에 값이 없는
return구문을 추가한다. - 해당 구문이 죽은 코드인지 검사한다. 죽은 코드라면 해당 함수는 올바르게 값을 반환하고 있다. 살아있는 코드라면 값을 반환하지 않는 경로가 존재하므로, 오류를 발생시킨다.
이렇게 CFG와 그 활용처에 대해 알아보았다. CFG는 컴파일러의 핵심중 하나이며, 매우 유용한 특성을 가진다. 우리는 이러한 특성을 이용해 프로그램에 대한 복잡한 검사를 손쉽게 수행할 수 있고, 이는 다양한 기능을 제공하는 현대 언어 구현에 지대한 영향력을 행사한다.
Conclusion
생각보다 글이 길어졌다. 이 글을 쓰기로 마음먹은 뒤로 상당한 시간이 지나서야 다 적을 수 있었다. 역시 내 머릿속에 있는 이야기를 문서로 작성하는 행위는 좀처럼 쉬운 일이 아닌 것 같다. 그래도 다 적으니 뿌듯하다. 아마 여태 작성한 글 중에서 가장 길지 싶은데.
나는 지금까지 몇 번에 걸쳐 컴파일러를 개발하려는 시도를 했었는데, 그 때마다 직면한 문제를 해결하지 못해 흥미를 잃고 포기해 버렸다. 문제를 해결하기 위해 나름대로 많이 찾아보고 공부했지만, 거의 대부분 이론적인 내용만 다루고 있었다. 실제 어떻게 구현해야하는지 노하우를 공유하는 곳은 사실상 찾아보기 어려웠다. 천만 다행으로, 이 프로젝트는 (어디까지나 주관적으로) 매우 완성도 있는 형태로 지금까지 왔다. 그 과정에서 내가 겪은 문제와 해결하기 위한 접근을 한국어로 공유하기 위해 이 글을 작성한다.
아무도 관심이 없겠지만, 이 프로젝트는 기본적인 문법과 컴파일 동작을 구현한 상태다. 상용 컴파일러가 되기 위해서는 훨씬 더 많은 언어 디자인과 구현이 필요하다. 앞으로 시간을 내서 조금씩 진행할 생각이다.